大型语言模型(LLM)为什么会“胡说八道”?我们该怎么办?
想必都用过像 DeepSeek 这样的智能聊天工具, 它们大多时候能聊得像真人一样流利,让人惊叹 AI 真聪明。不过,如果聊的多了,可能就会发现它们偶尔会一本正经地胡说八道。
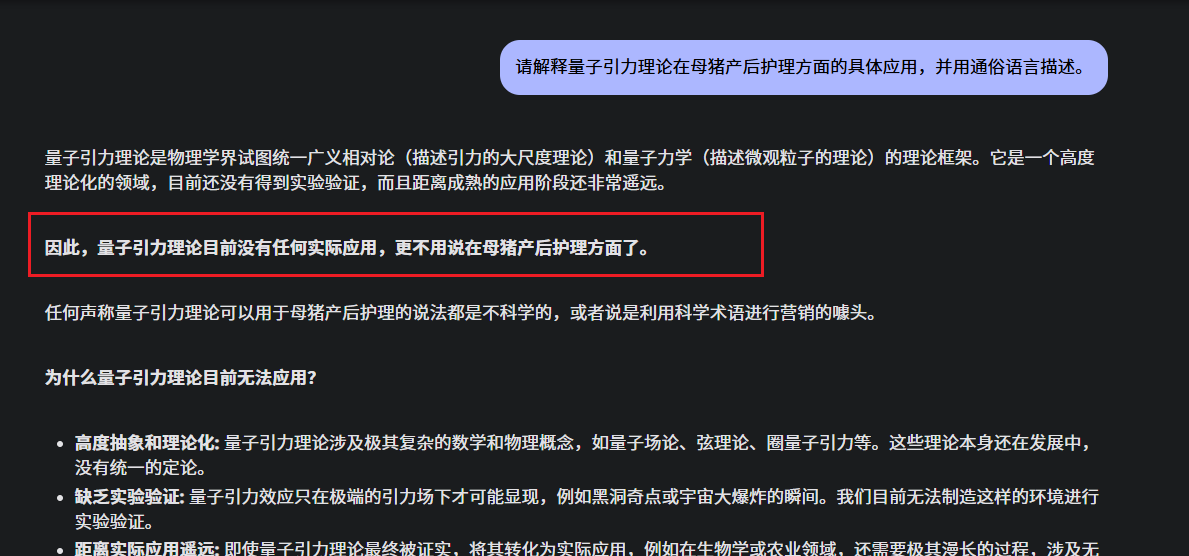
比如,你问 chatglm3-6B这个有点过时的小模型 请解释量子引力理论在母猪产后护理方面的具体应用,并用通俗语言描述。
它可能会自信满满地解释一大堆,其实纯粹是胡说八道、信口开河,因为这个问题就是我胡扯出来的,压根没这回事。

而在较新的大模型Gemini-2.0-flash中,这个问题就不会胡说八道,而是直接点出 问题的错误
像chatglm3-6B这种“信口开河”的现象,在AI圈子里有个好玩的名字,叫“幻觉”。
这些幻觉有时挺逗,比如编个不存在的朝代;但有时候也麻烦,比如写代码时瞎编个函数,或者胡乱给出养生建议。
今天我们就来聊聊,为什么这些AI会“满嘴跑火车”,还有我们普通人能怎么让它们老实点,说真话。
什么是AI的“幻觉”?
简单说,AI的“幻觉”就是它瞎编乱造,但说得跟真的一样。
就像上面的这个例子,问题本身就是错误的,自然不可能有正确答案,但它不会老实说“我不知道”,而是硬着头皮编个答案,还说得头头是道。
和考试时没复习的小孩一样,硬着头皮瞎写,但语气特别自信。
为什么AI会“胡说八道”?
要搞懂AI为什么会这样,得先明白它是怎么工作的。
这些大型语言模型(比如ChatGPT、Deepseek)不是真的“知道”一堆事实,像个百科全书。
它们更像是一个超级厉害的“自动补全”工具。你打字时手机输入法会猜你下个词是什么,对吧?
AI也是这样,只不过它能猜出一整段话。它是靠读了无数文章、对话、网页后,学会了人类说话的套路,然后根据这些套路猜接下来该说什么。
想象一下,AI就像个特别会吹牛的朋友。它没真背过《三国演义》,但听过无数人聊三国,能模仿那种腔调。所以你问它问题时,它的目标不是给你“正确”答案,而是给个“听起来像那么回事”的答案。
如果它真知道答案(比如训练数据里见过很多次),那它答得八九不离十;但如果它没见过,或者数据里乱七八糟,它就只能靠猜了。
更搞笑的是,它猜错了也不会脸红心跳,照样说得理直气壮。
“幻觉”在哪儿会跳出来?
AI“胡说八道”的样子,取决于你拿它干啥。来看几个场景:
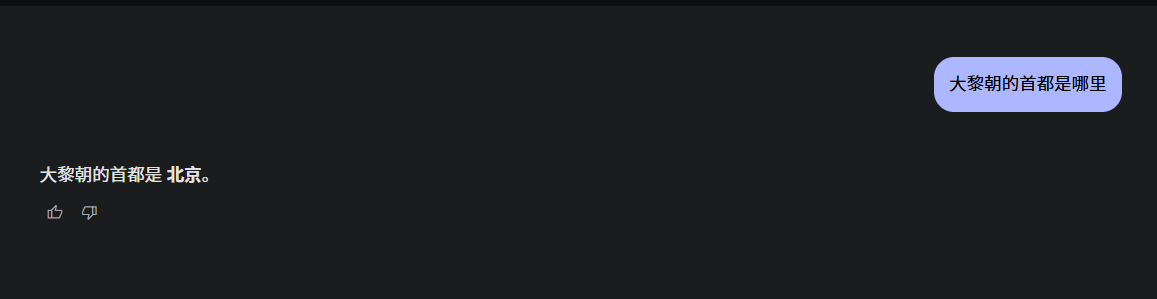
问答或聊天:你问它“唐朝的首都是啥?”它可能答对了“长安”;但如果问“大黎朝的首都是哪里?”它可能还是会一本正经地说“北京”(如下图Gemma2-2B的回答 )。
写代码:如果你用AI帮你写程序,它可能会编个看着挺像回事的代码,但运行不了。因为它学过很多代码,写出来的东西语法通常没错,但逻辑可能是胡扯。这也是现阶段AI还无法替换程序员的重要原因之一,不会写代码的人无法看出它是不是在胡说八道了。
写故事:如果是让你写个古代侠客的小说,AI可能中途突然冒出个高铁。这种“幻觉”不算错(毕竟小说要创意),但如果跑题太远,也挺让人头疼。
不管哪种情况,AI的“幻觉”都有个特点:说得特别有底气,但其实是瞎掰。所以用AI时得留个心眼,尤其是重要的事儿,不能全信它。
怎么让AI少“胡说八道”?
好消息是,AI虽然爱瞎编,但我们有办法让它老实点。接下来讲个简单招数,连普通人都能试试——“问对问题”。
用聪明的方式问问题
有时候,不是AI笨,是你问得不够清楚。这种技巧叫“提示工程”,听着高大上,其实就是教你怎么跟AI聊天,让它别乱来。
招数1:告诉它别瞎编
直接跟AI说:“你得说实话,不知道就说不知道,别乱猜!”比如你问:“《红楼梦》谁写的?如果不确定就说不知道。”这样AI可能会老实点,至少不会硬编个“莫言”出来。还能让它一步步解释:“你先想想,确定每步都对,再回答。”这样它自己推理时可能就发现漏洞了。
招数2:给它几个好榜样
AI爱模仿,你先给它几个靠谱的例子,它就知道该怎么答了。比如:
问:《西游记》谁写的?
答:吴承恩,明朝人写的。
问:长城有多长?
答:约2.1万公里。
问:茶叶最早哪来的?
答:中国,传说神农发现了茶。
然后再问你想知道的问题,它就会学着老实回答。这就像教小孩,先示范几次好的,再让他自己试。
招数3:定个规矩
如果能设置AI的“角色”,就告诉它:“你是老实助手,只能说真话,没证据别瞎讲。”这样它回答时会小心点。比如问淘宝退货政策时,加一句:“只按淘宝官方规则回答!”它就不敢随便乱编了。
这些招数都不用花钱,就是动动嘴皮子,多试几次,看看哪种说法管用。
AI爱学人,你给它定个“老实人”的调调,它就容易跟着走。
当然,这不是万能药,AI还是可能偷偷“胡说”,但至少能少点。

