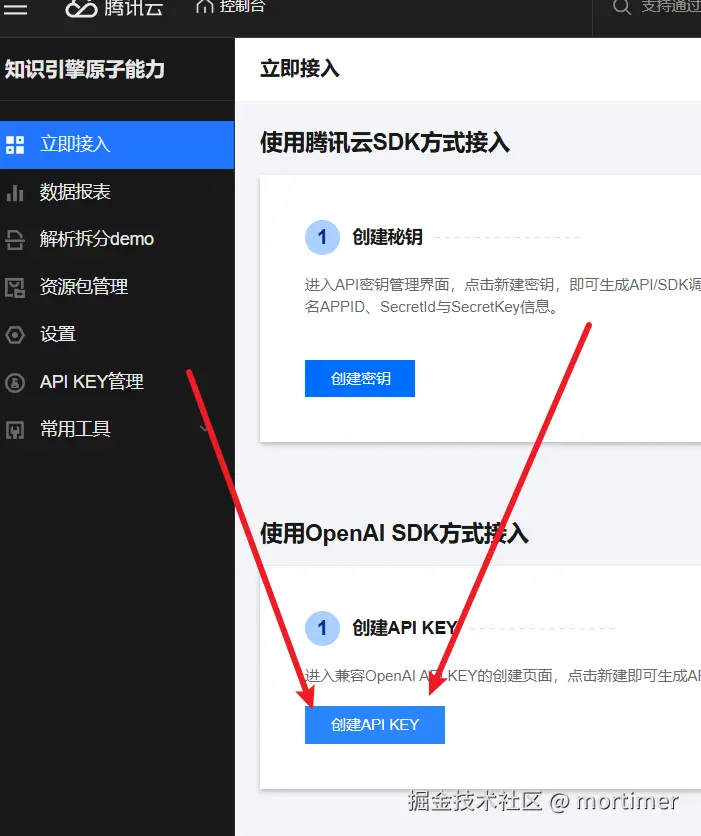
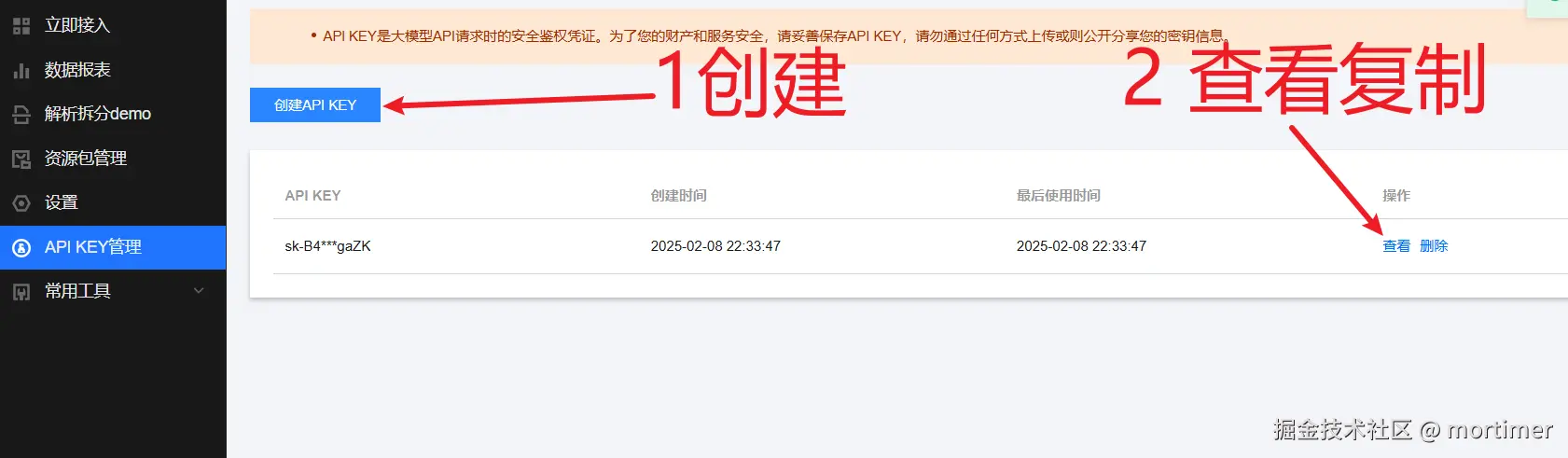
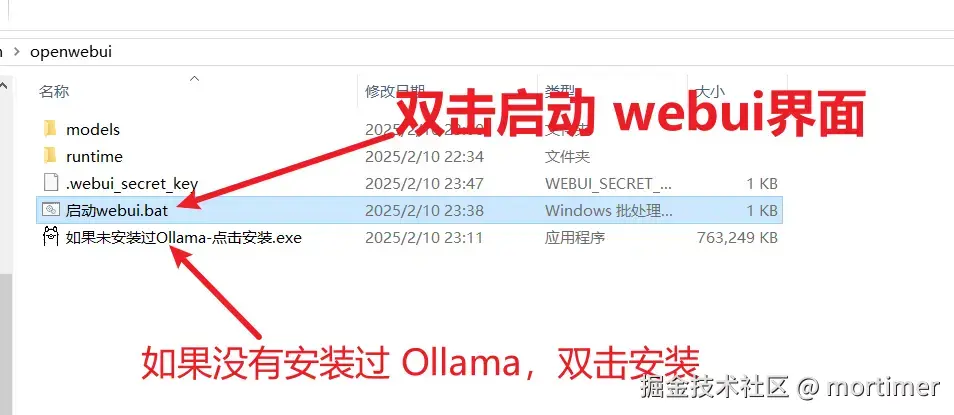
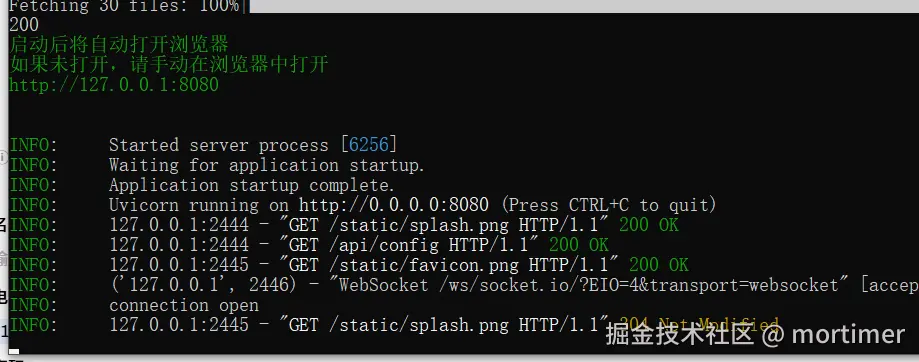
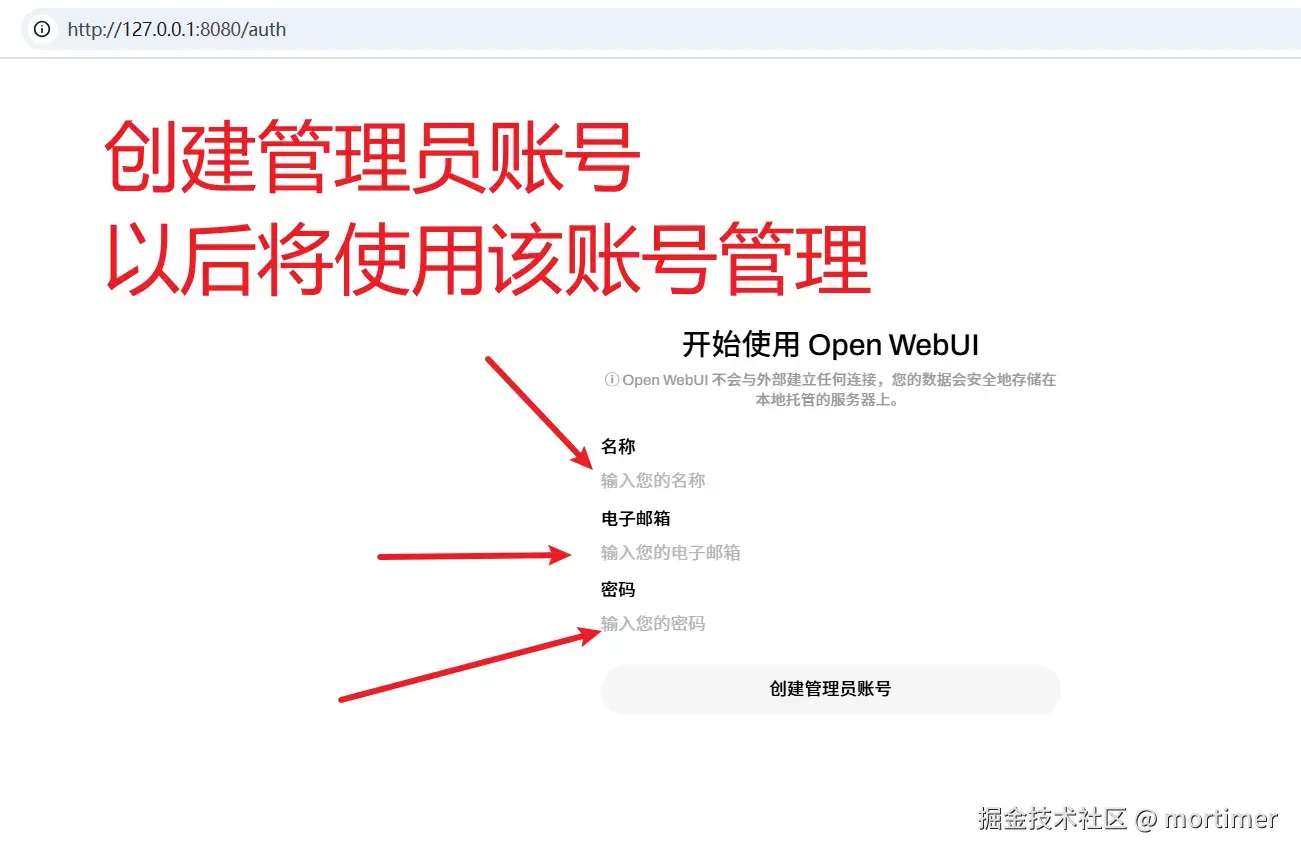
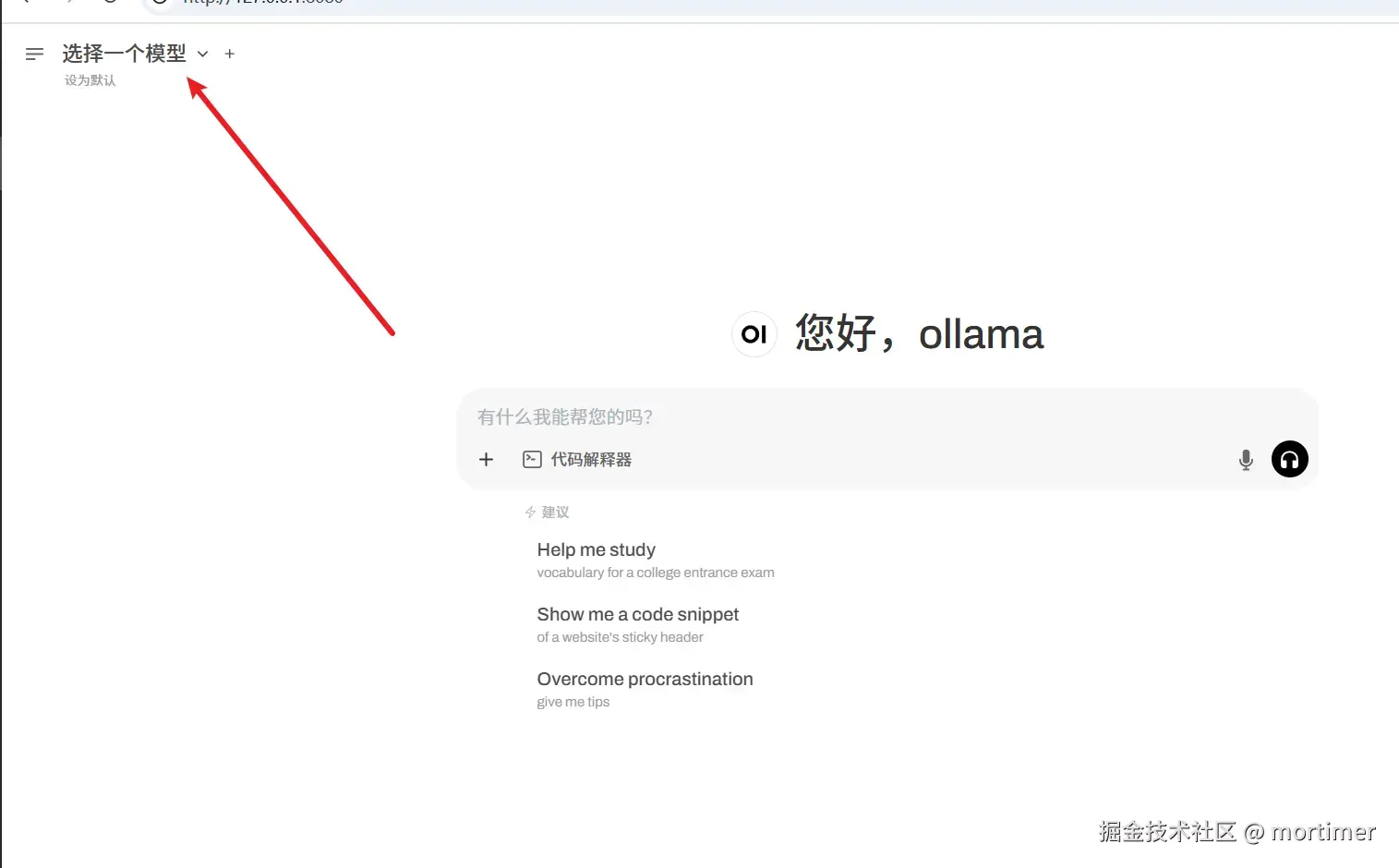
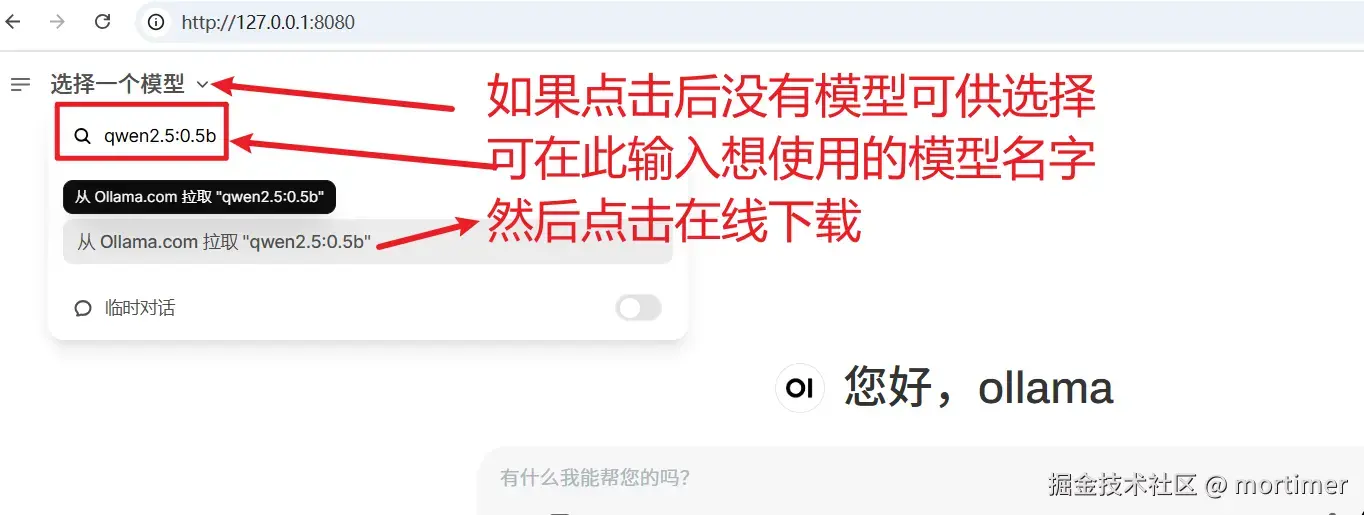
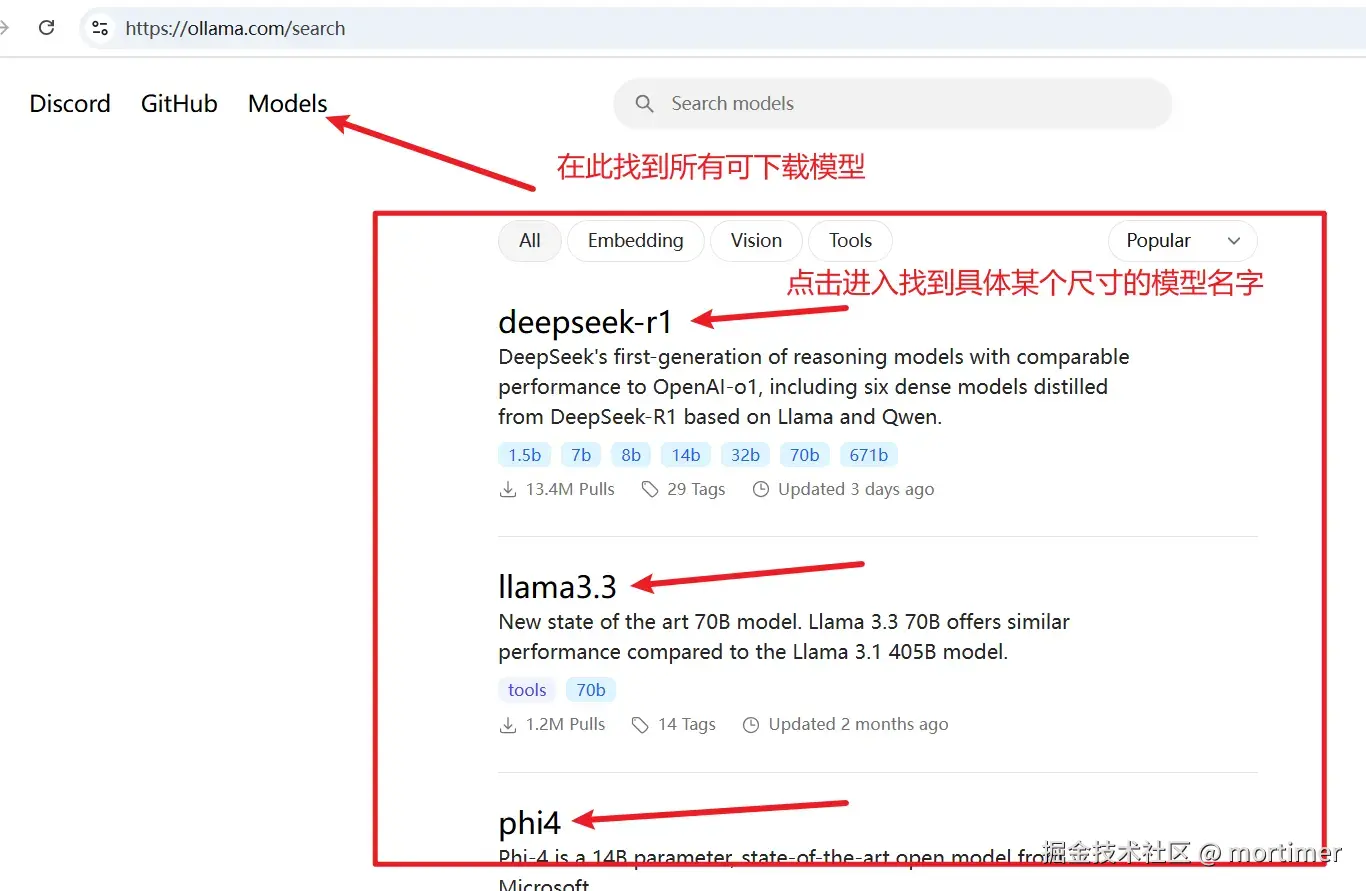
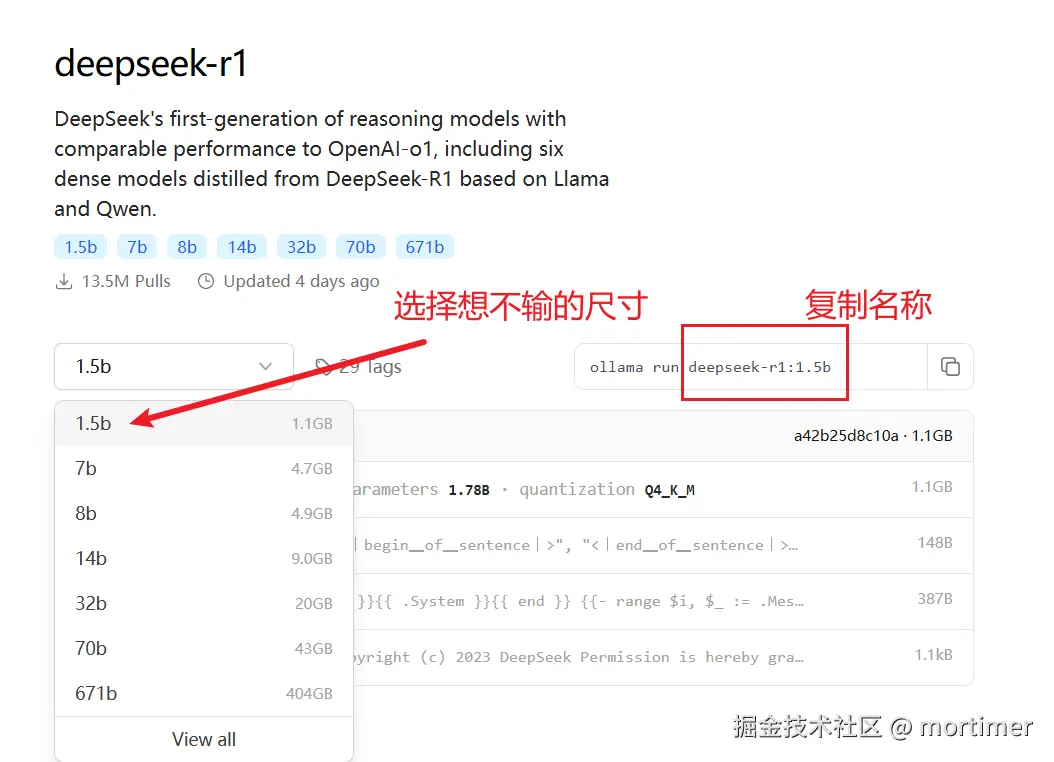
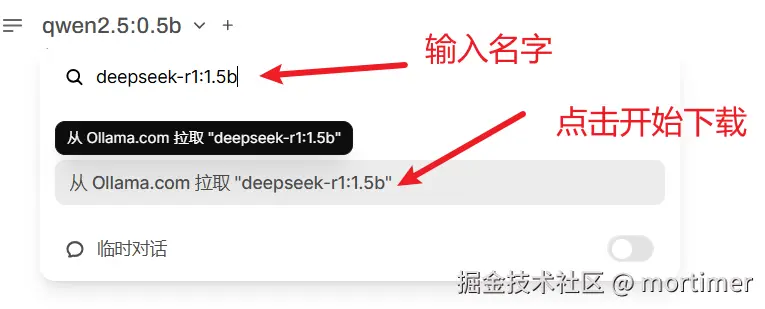
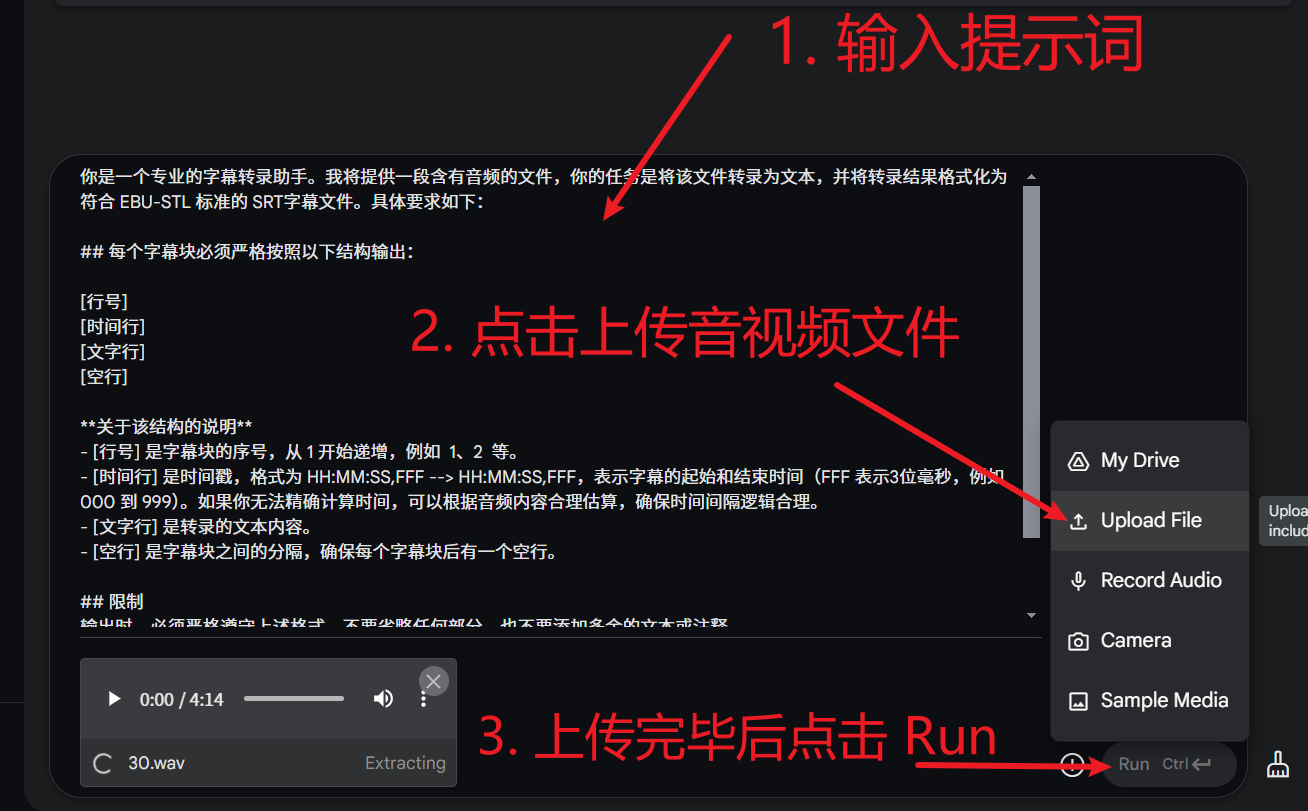
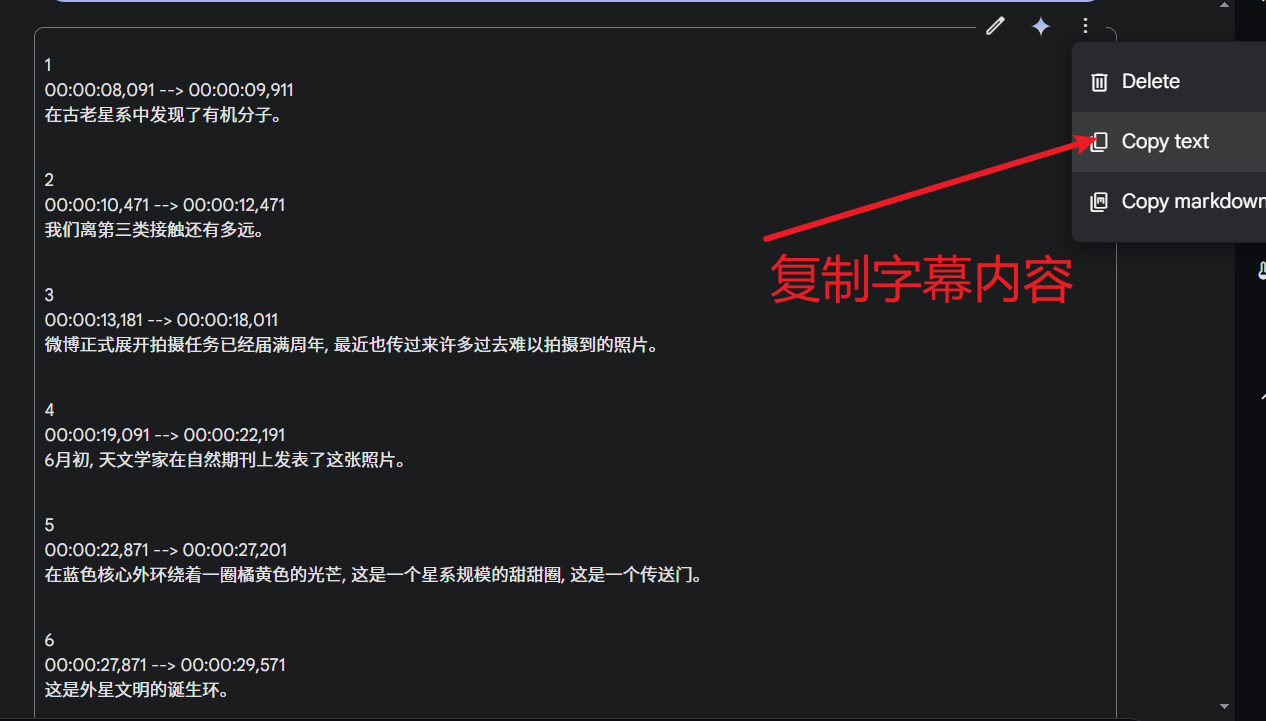
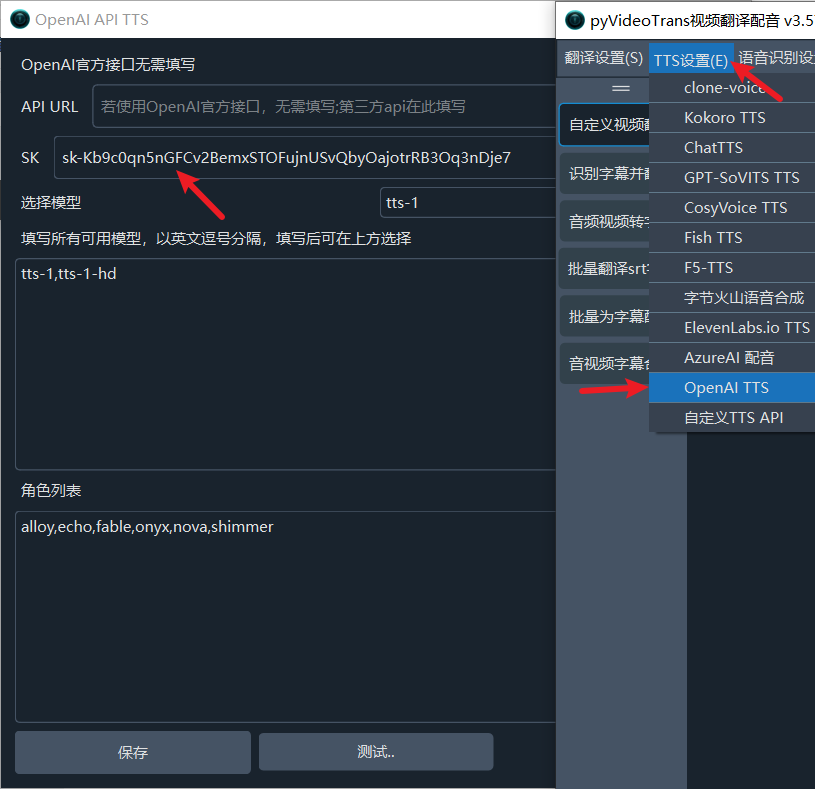
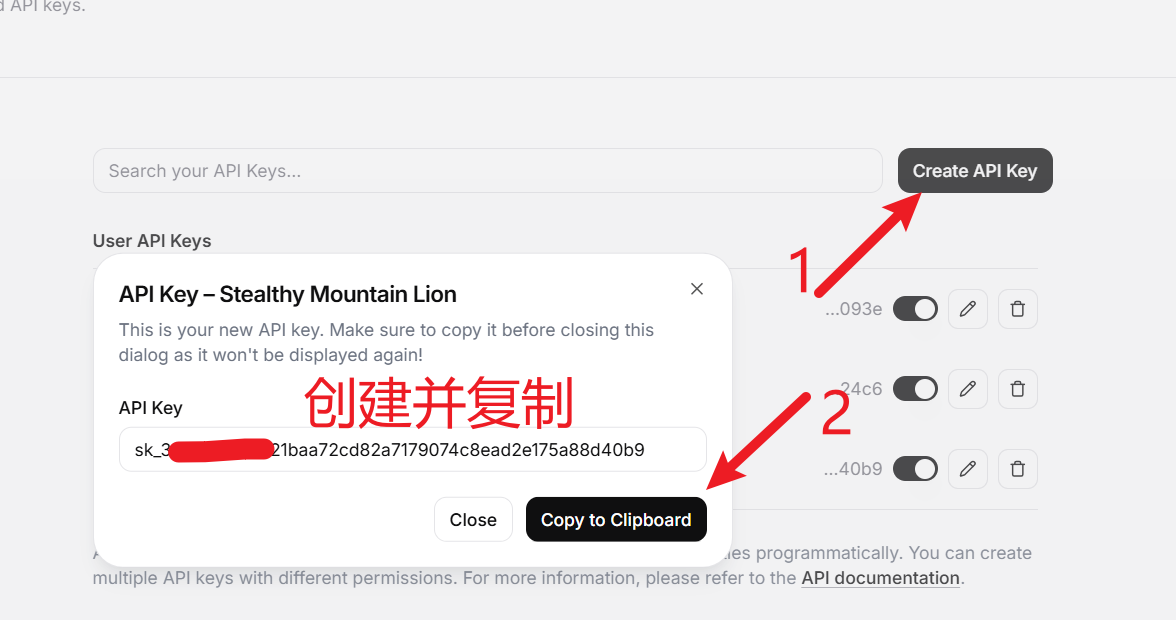
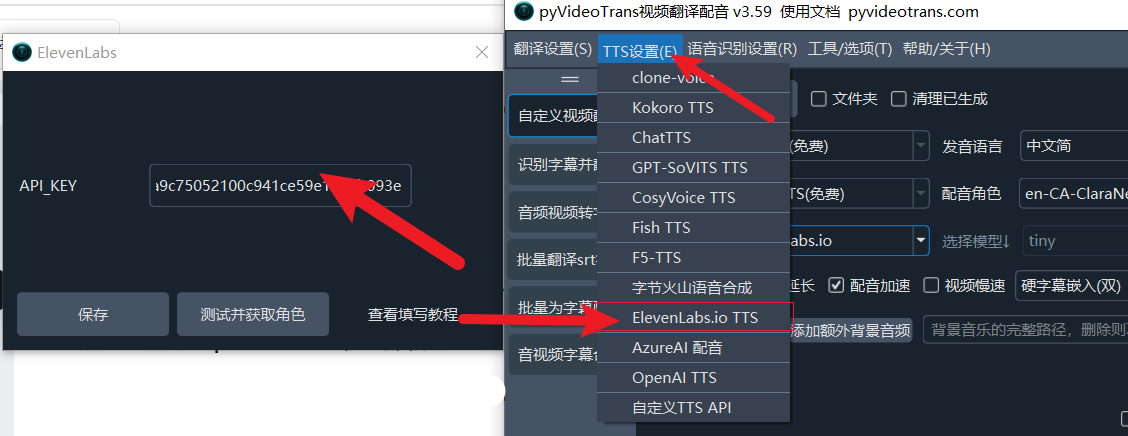
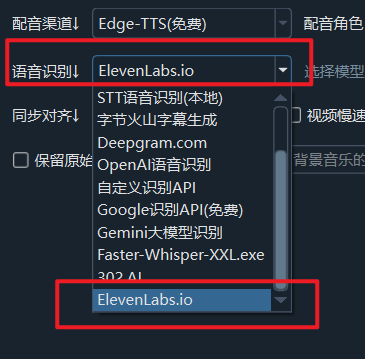
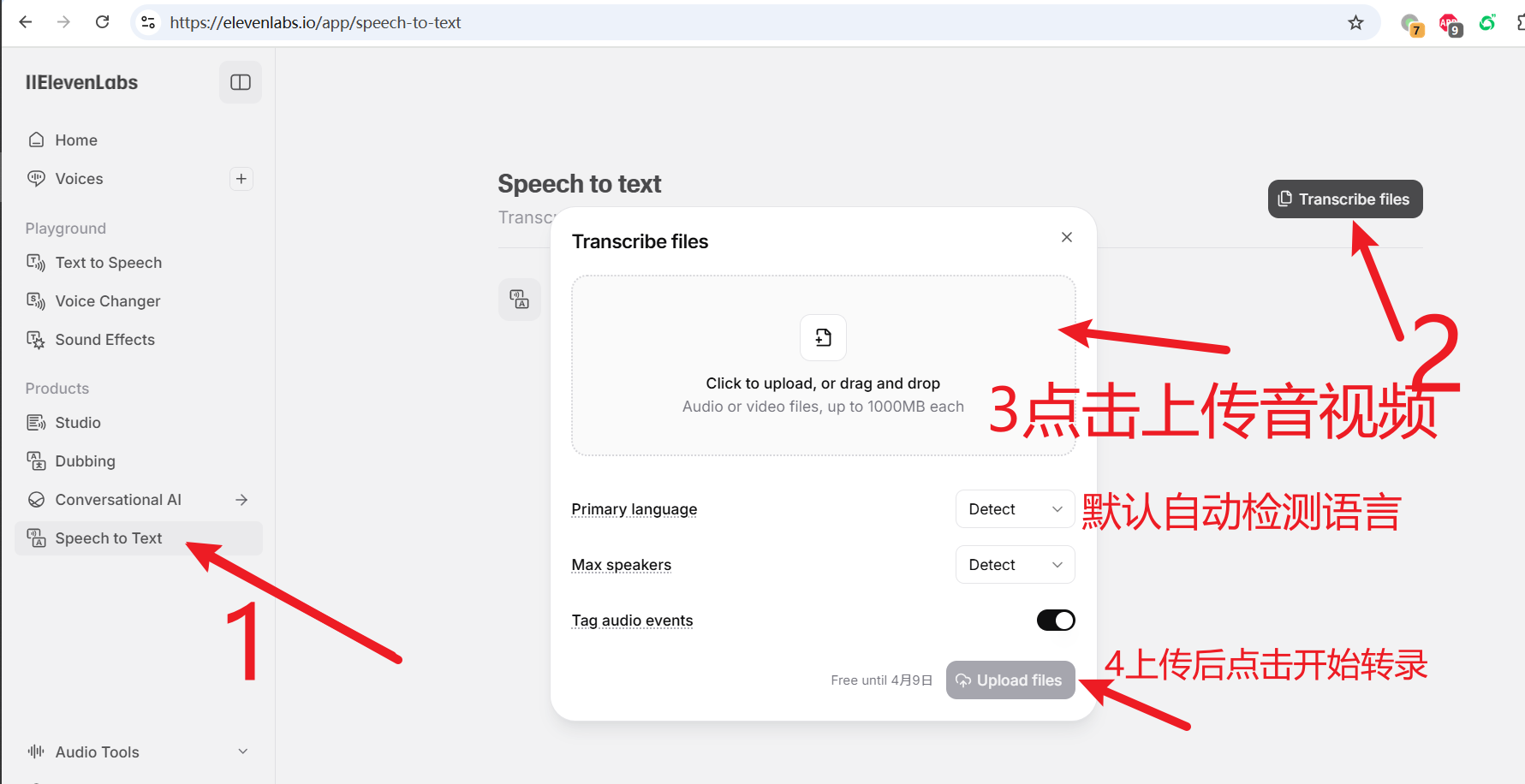
自 OpenAI ChatGPT-3 爆火后,AI领域发展迅速,涌现出不少优秀的AI服务,幸运的是,大多都兼容OpenAI SDK 格式,无需改动代码,直接修改 API URL、API KEY、模型名字即可无缝替换。
以下整理了几个常用的 AI服务商及AI大模型市场信息,方便替换使用。包括国外和国内,以及是否有免费额度等。
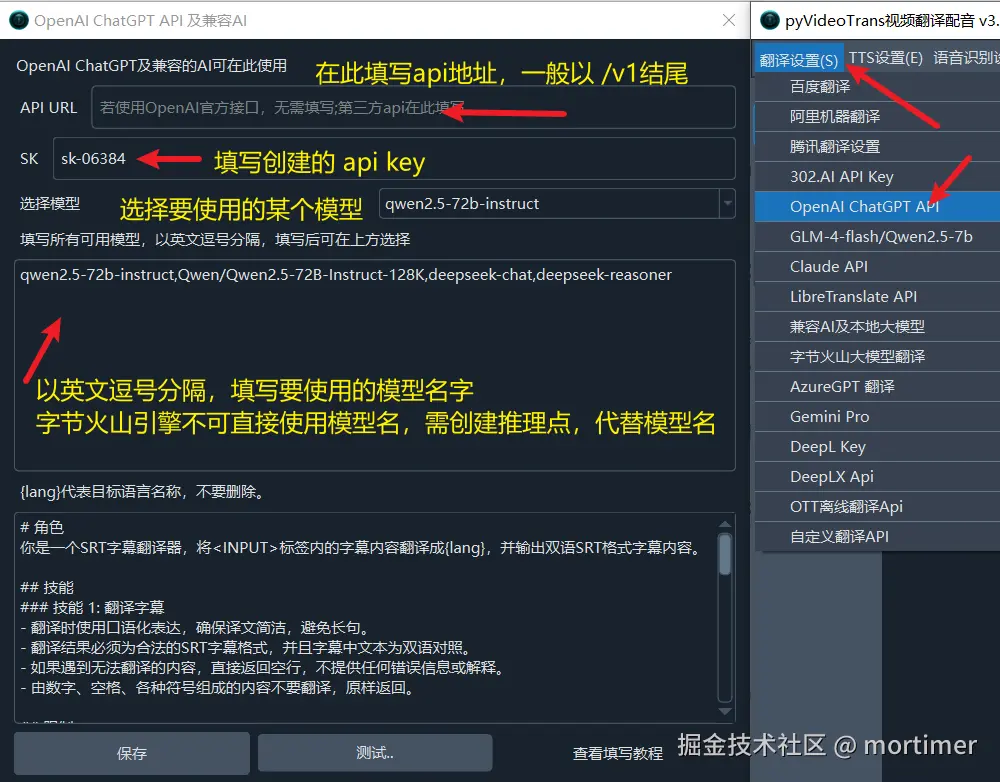
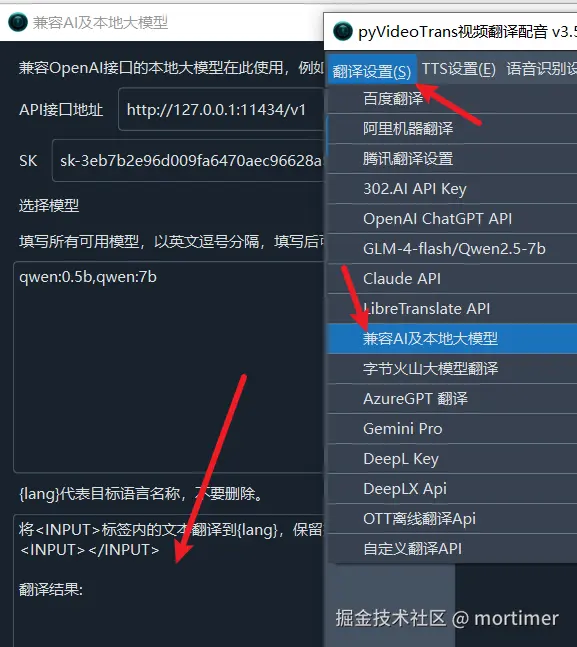
API URL 是指在使用中需要指定的 api 接口地址
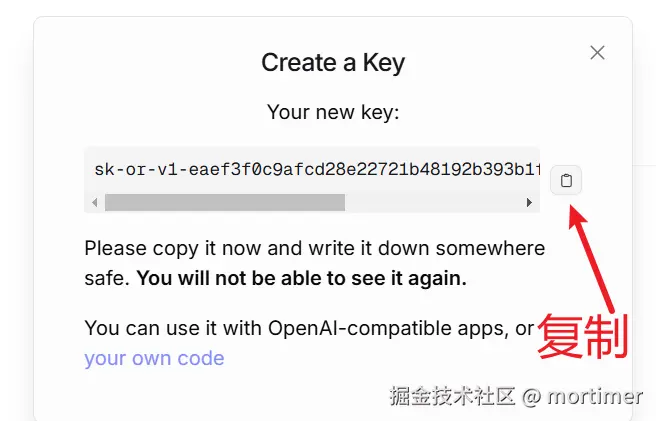
API KEY 是指调用该接口的密钥/SK
AI模型市场一般支持众多模型,可打开模型详情页查看
API 免费额度是指:是否允许在未付费情况下,通过代码调用。
OpenAI(当世最佳)
使用需VPN,付费需国外信用卡
官网: https://chatgpt.com/auth/login
API KEY获取地址: https://platform.openai.com/api-keys
API URL: https://api.openai.com/v1
可用模型: https://platform.openai.com/docs/models
API免费额度: 每分钟最多3次请求。每日最多200次请求
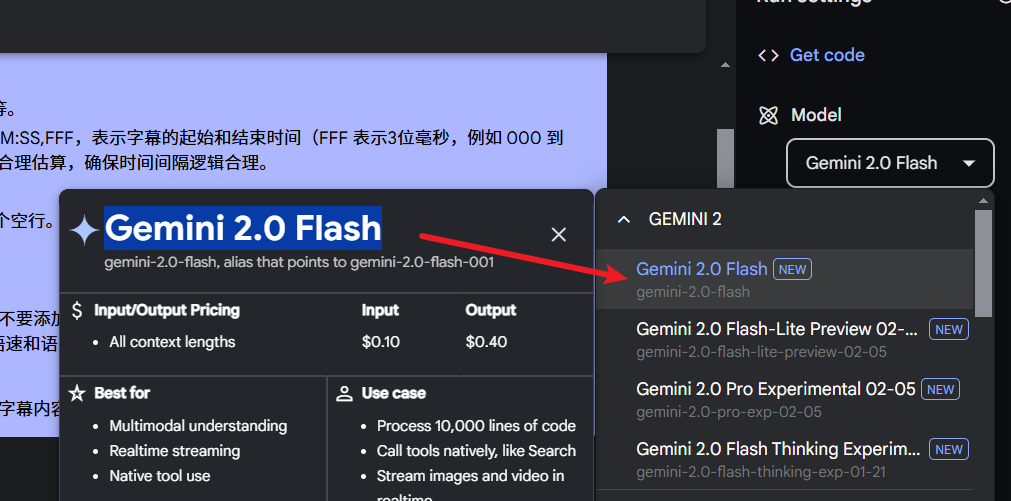
Gemini(Google出品)
使用需VPN,付费需国外信用卡
官网: https://aistudio.google.com
API KEY获取地址: https://aistudio.google.com/apikey
API URL: https://generativelanguage.googleapis.com/v1beta/openai/
可用模型: gemini-2.0-flash/gemini-1.5-flash/gemini-2.0-pro-exp-02-05/gemini-1.5-pro
API免费额度: 每日 1500 次调用
Claude
使用需VPN,付费需国外信用卡
官网: https://claude.ai
API KEY地址: https://console.anthropic.com/settings/keys
API URL: https://api.anthropic.com/v1
可用模型: https://docs.anthropic.com/en/docs/about-claude/models
API免费额度: 无免费额度
XAI(马斯克的)
需VPN,付费需国外信用卡
官网: https://x.ai
API KEY地址: https://console.x.ai
API URL: https://api.x.ai/v1
可用模型: grok-2-1212、grok-2-vision-1212
API免费额度: 充值5美元后,美元可获赠 $150 额度
groq(ai模型市场)
需VPN,付费需国外信用卡
官网: https://console.groq.com
API KEY地址: https://console.groq.com/keys
API URL: https://api.groq.com/openai/v1
可用模型: 众多 https://console.groq.com/docs/models
API免费额度: 大多模型均有免费额度,每日1000到10000不等
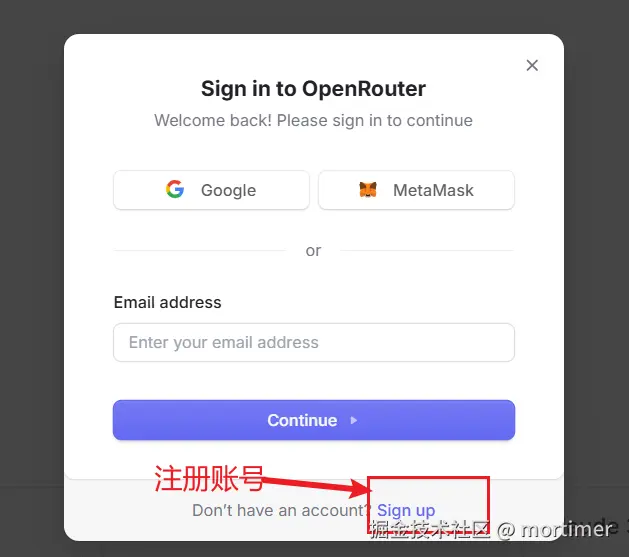
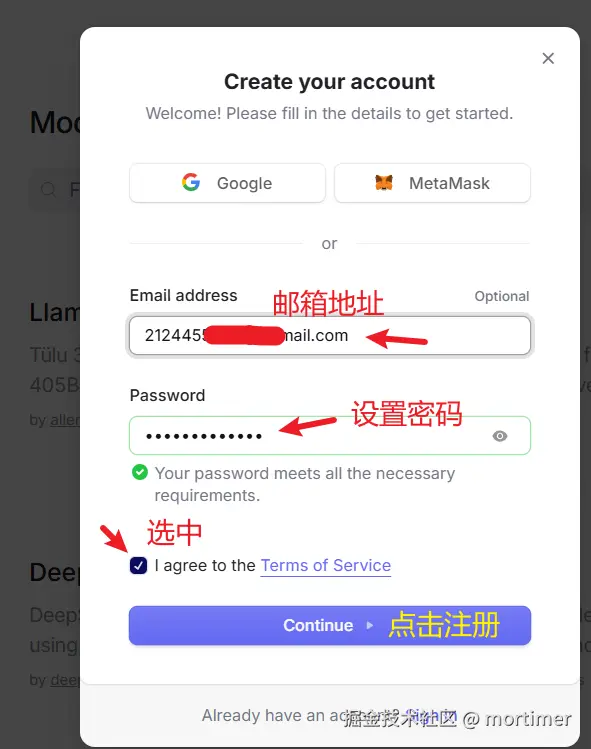
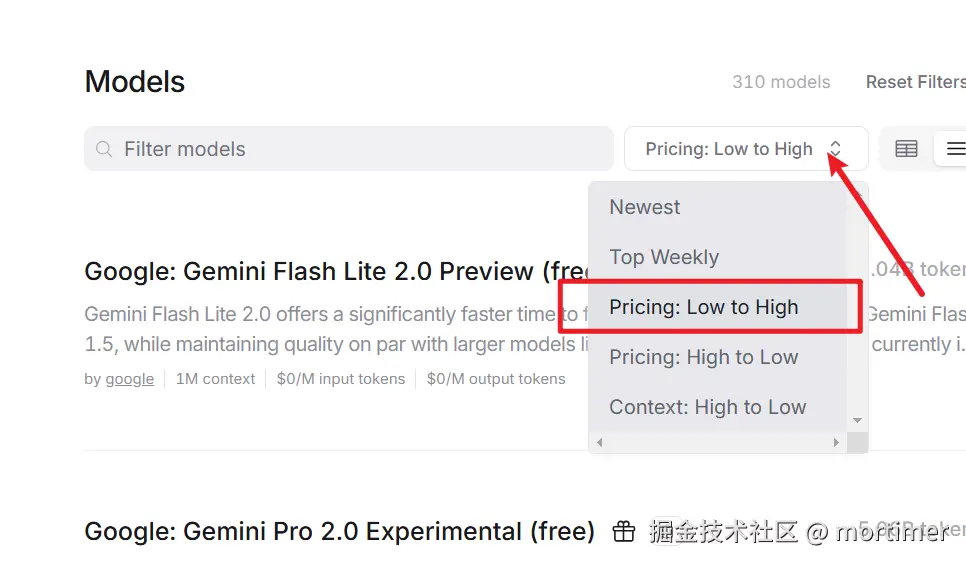
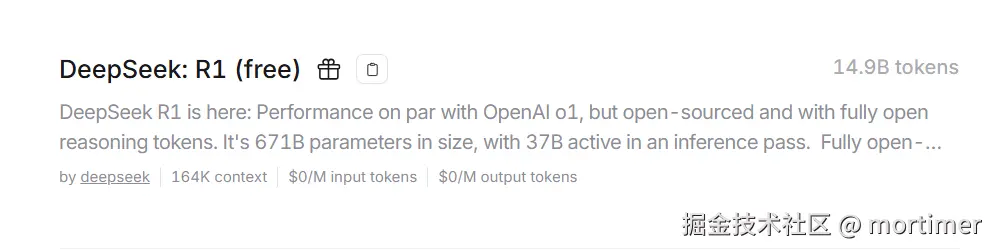
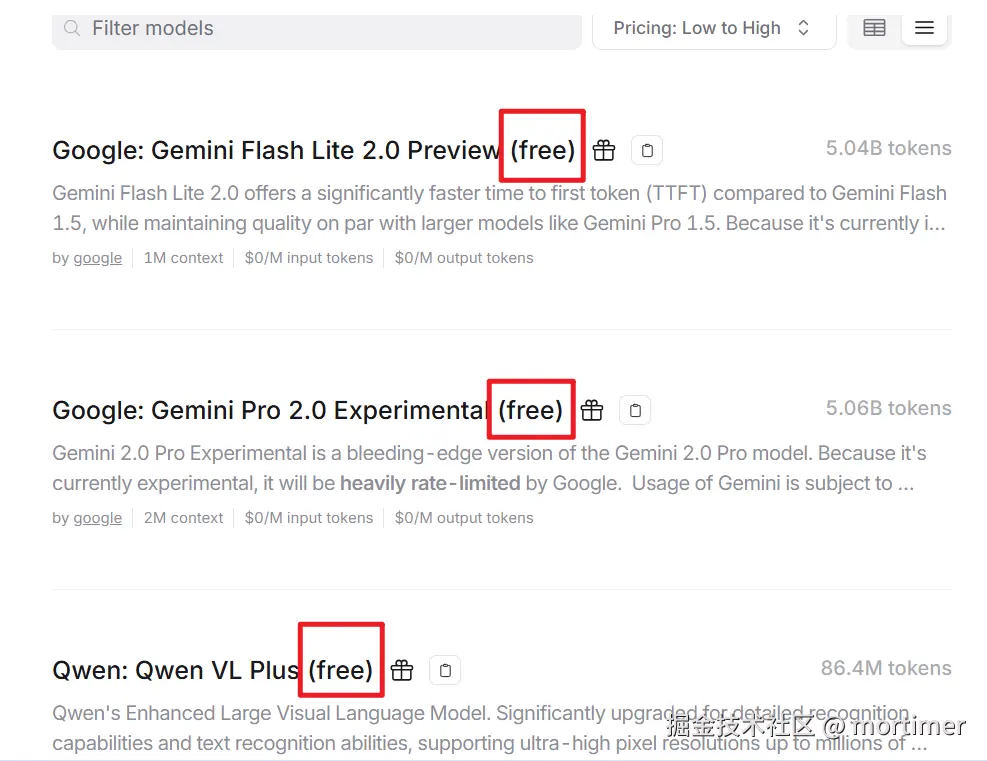
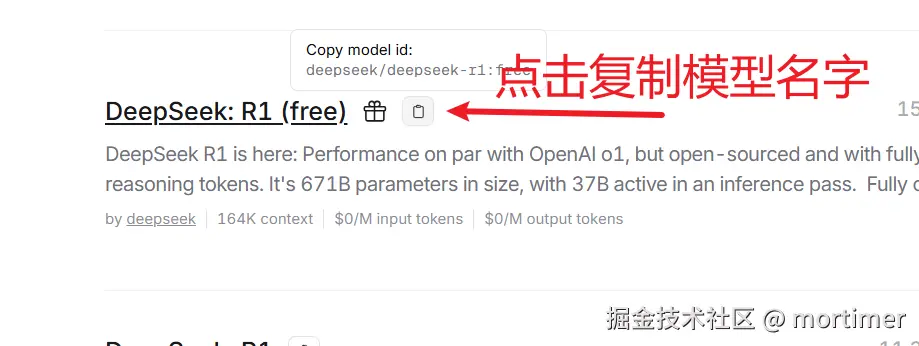
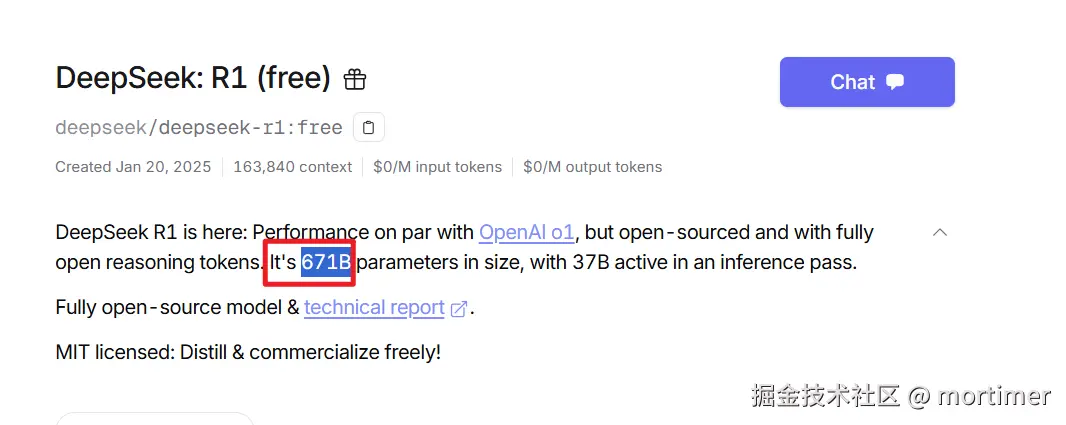
openrouter.ai(ai模型市场)
官网: https://openrouter.ai
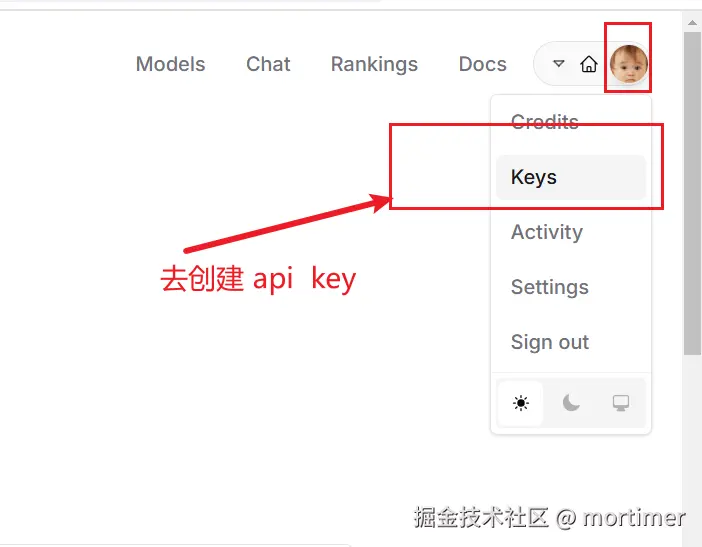
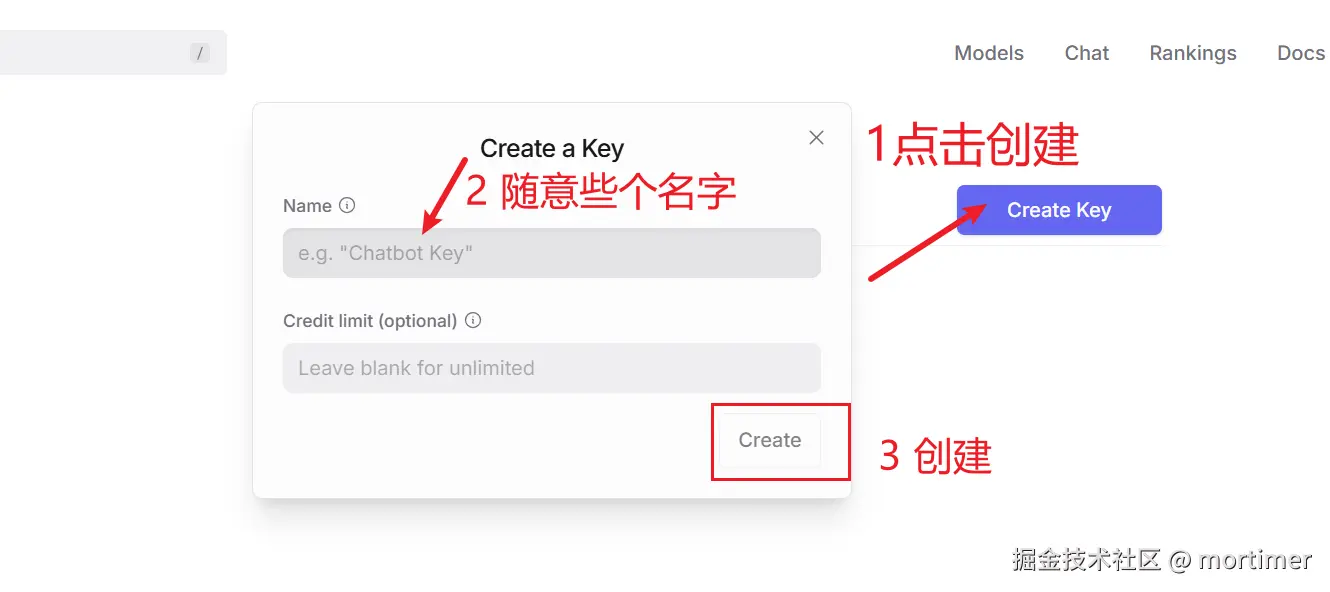
API KEY地址: https://openrouter.ai/settings/keys
API URL: https://openrouter.ai/api/v1
可用模型: 众多,https://openrouter.ai/models
API免费额度: 有免费模型,每日200次调用
Deepseek 深度求索
这是 Deepseek的官方 API 服务,不过近期不稳定
官网地址: https://www.deepseek.com
API KEY(SK)获取地址: https://platform.deepseek.com/api_keys
API URL: https://api.deepseek.com/v1
可用模型: deepseek-chat :即v3模型 、 deepseek-reasoner即R1推理模型
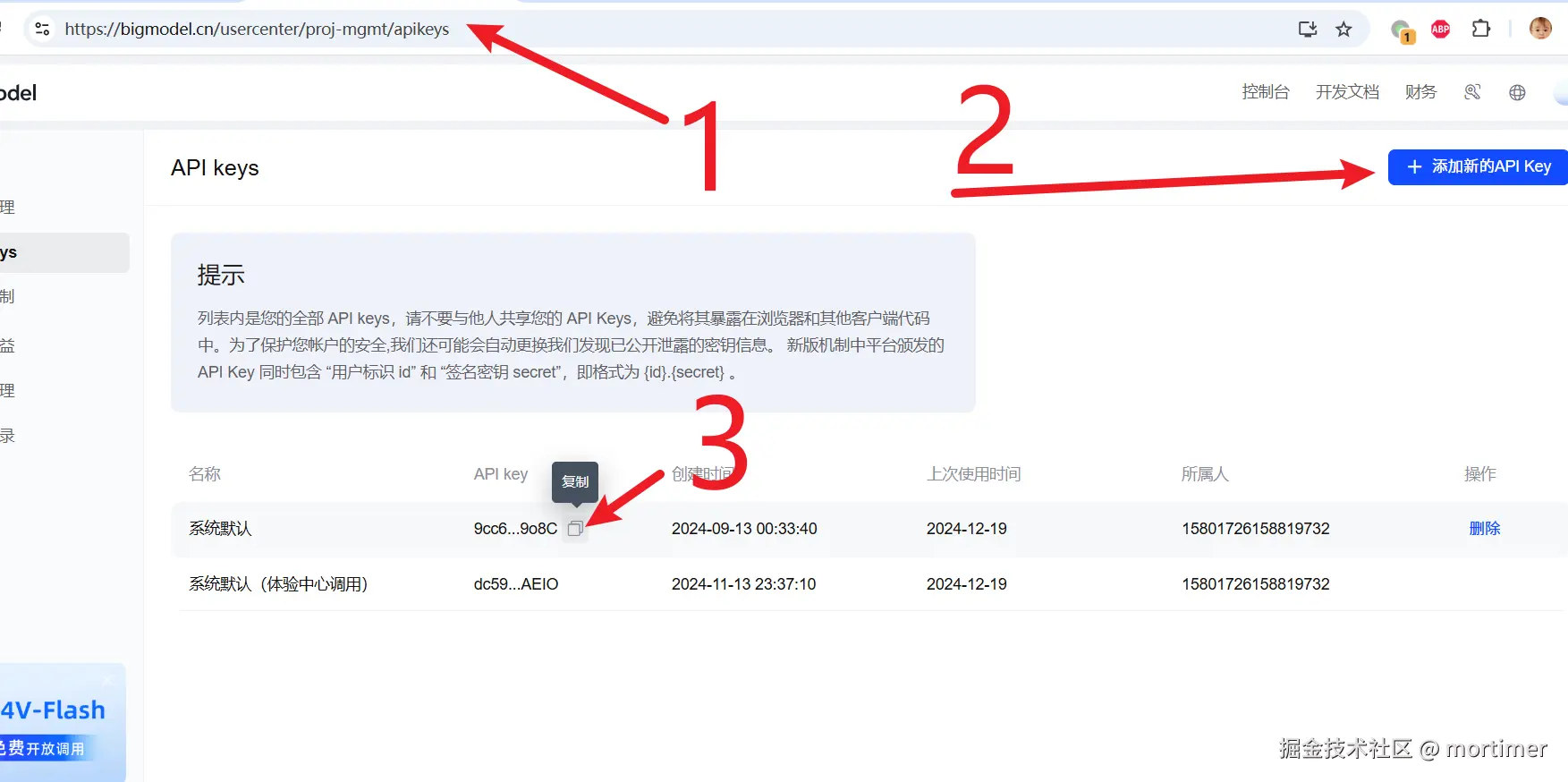
智谱AI
官网地址: https://bigmodel.cn
API KEY(SK)获取地址: https://bigmodel.cn/usercenter/proj-mgmt/apikeys
API URL: https://open.bigmodel.cn/api/paas/v4
可用模型 : glm-4-plus、glm-4-air、glm-4-air-0111 、glm-4-airx、glm-4-long 、glm-4-flashx 、glm-4-flash
API免费额度: glm-4-flash 是免费模型
百川智能
官网地址: https://www.baichuan-ai.com
API KEY(SK)获取地址: https://platform.baichuan-ai.com/console/apikey
API URL: https://api.baichuan-ai.com/v1
可用模型: Baichuan4-Turbo 、Baichuan4-Air、Baichuan4、Baichuan3-Turbo、Baichuan3-Turbo-128k、Baichuan2-Turbo
月之暗面 Kimi
官网: https://www.moonshot.cn
API KEY(SK)获取地址: https://platform.moonshot.cn/console/api-keys
API URL: https://api.moonshot.cn/v1
可用模型: moonshot-v1-8k、moonshot-v1-32k 、moonshot-v1-128k
零一万物
官网: https://lingyiwanwu.com
API KEY获取地址: https://platform.lingyiwanwu.com/apikeys
API URL: https://api.lingyiwanwu.com/v1
可用模型: yi-lightning
阿里百炼(ai模型市场)
阿里百炼是AI模型集市,提供了所有阿里系模型及其他厂家模型,包括 Deepseek-r1
官网地址: https://bailian.console.aliyun.com
API KEY(SK)获取地址: https://bailian.console.aliyun.com/?apiKey=1#/api-key
API URL: https://dashscope.aliyuncs.com/compatible-mode/v1
可用模型: 众多,具体查看 https://bailian.console.aliyun.com/#/model-market
API免费额度: 多数模型有免费额度
硅基流动(ai模型市场)
又是一个类似阿里百炼的AI集市,提供了国内主流模型,包括 deepseek-r1
官网地址: https://siliconflow.cn
API KEY(SK)获取地址: https://cloud.siliconflow.cn/account/ak
API URL: https://api.siliconflow.cn/v1
可用模型: 众多,具体查看 https://cloud.siliconflow.cn/models?types=chat
API免费额度: 有免费模型,无需花费可直接使用
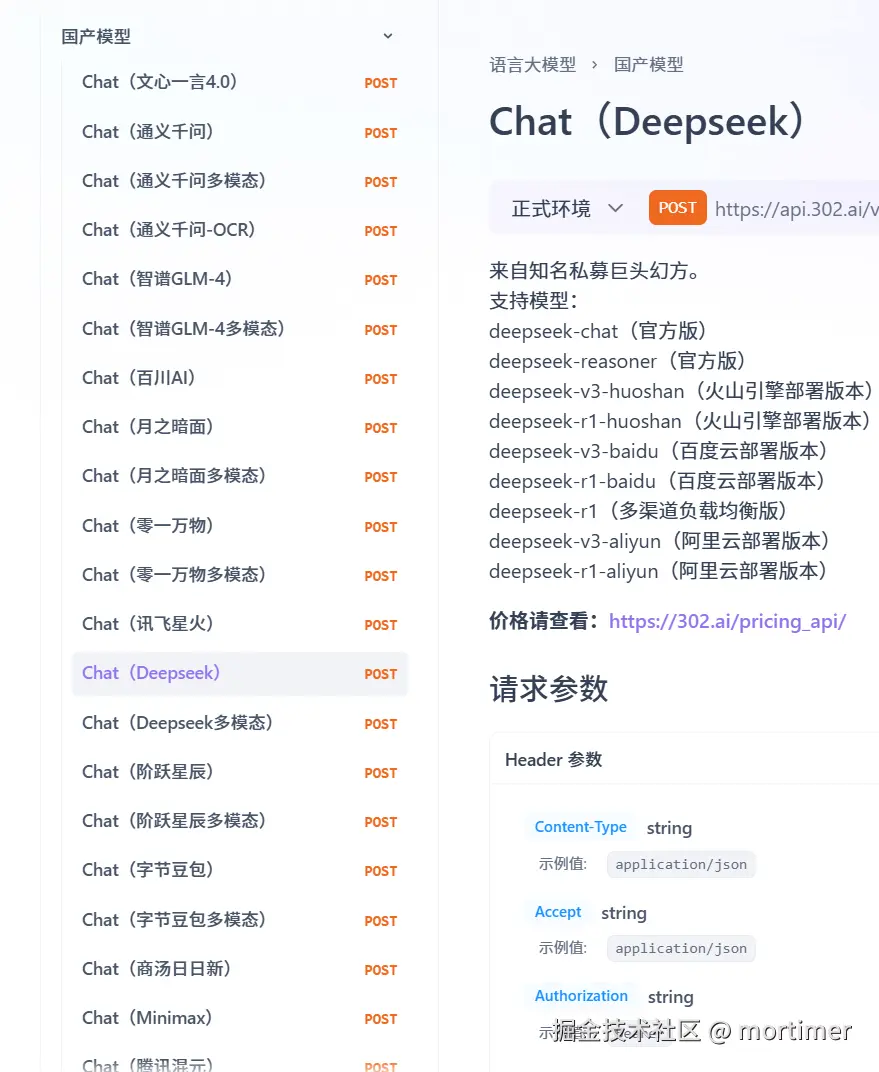
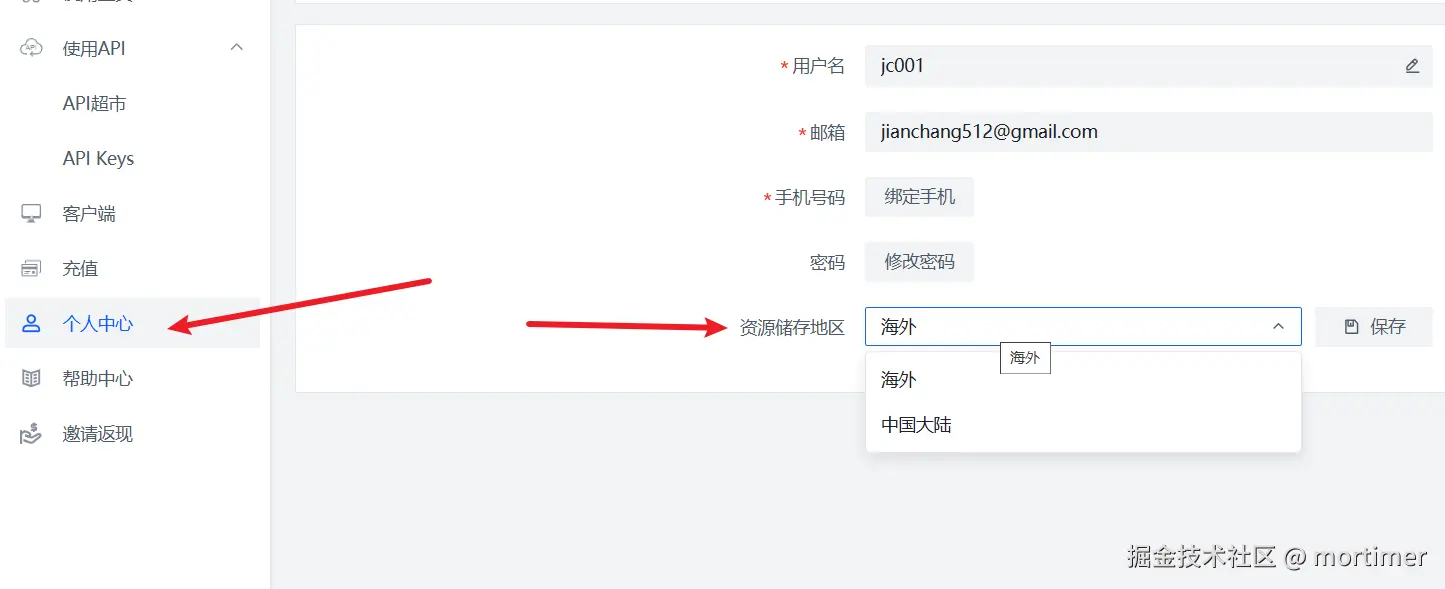
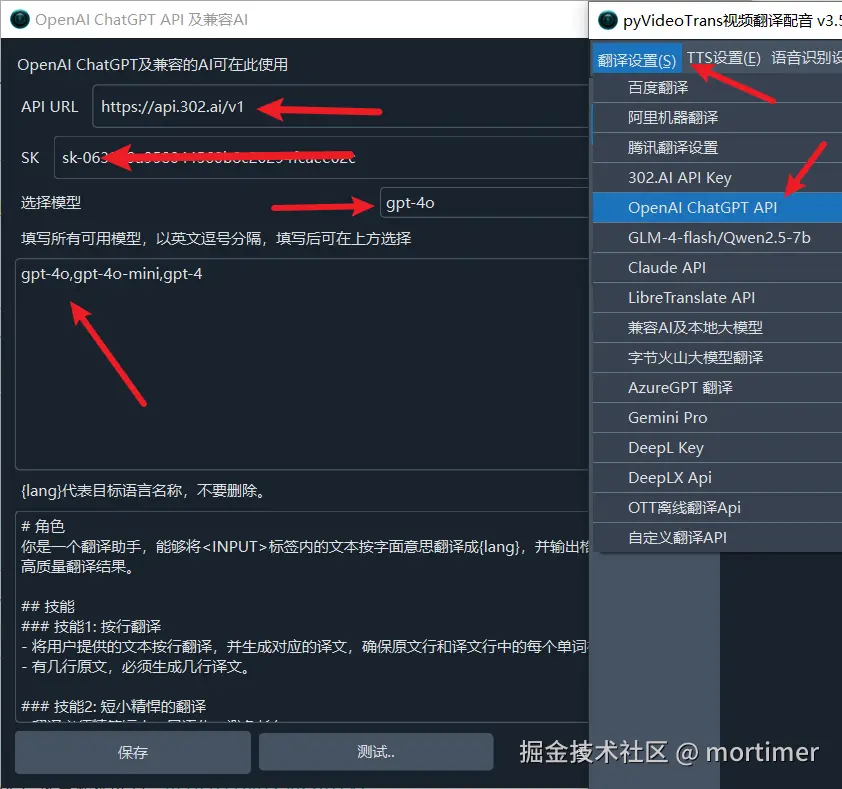
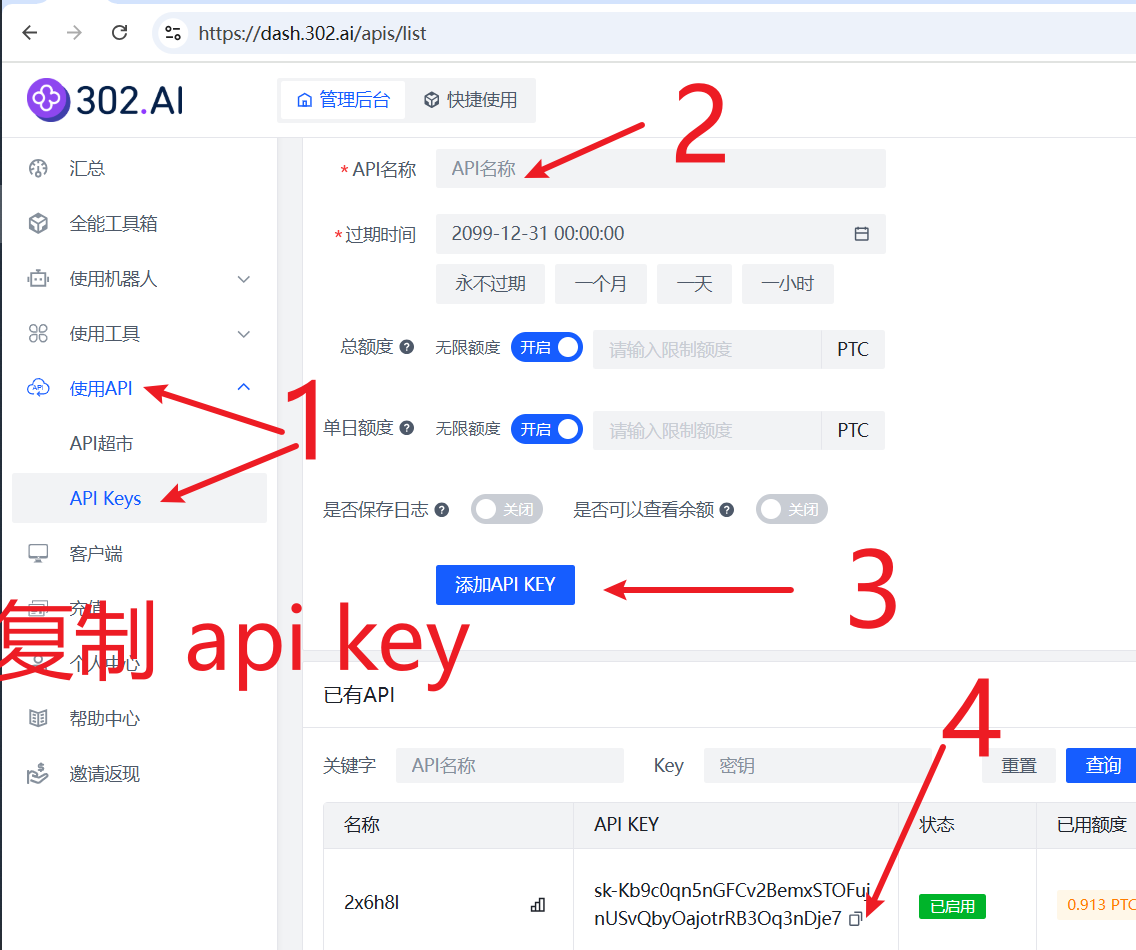
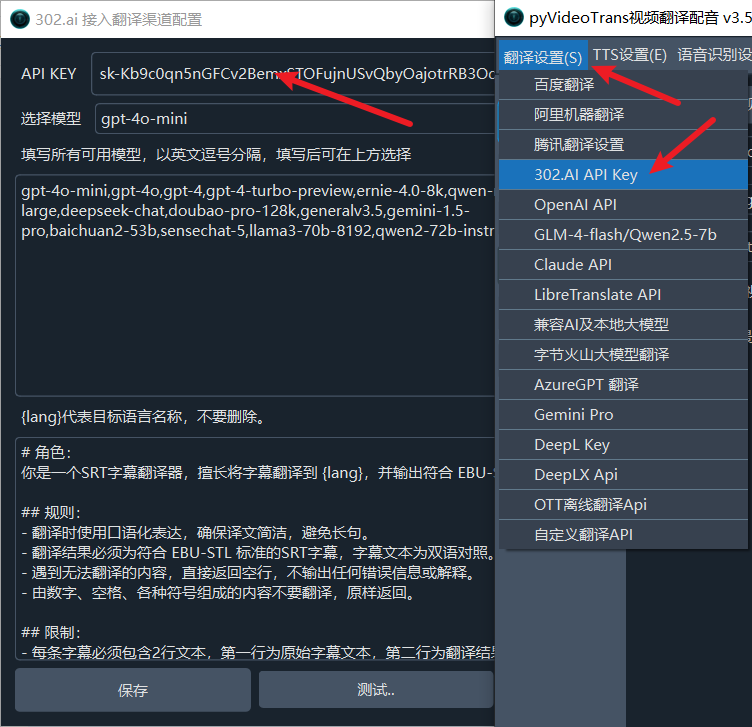
302.AI(ai模型市场)
又是一个类似阿里百炼的AI集市,提供了国内主流模型,包括 deepseek-r1
官网地址: https://302.AI
API KEY(SK)获取地址: https://dash.302.ai/apis/list
API URL: https://api.302.ai/v1
可用模型: 众多,具体查看 https://302ai.apifox.cn/api-147522039
字节火山方舟(ai模型市场)
类似阿里百炼的AI集市,除了汇集豆包系列模型,还有一些第三方模型,包括 deepseek-r1
官网: https://www.volcengine.com/product/ark
API KEY(SK)获取地址: https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey
API URL: https://ark.cn-beijing.volces.com/api/v3
MODELS: 众多,具体查看 https://console.volcengine.com/ark/region:ark+cn-beijing/model?vendor=Bytedance&view=LIST_VIEW
API免费额度: 有免费额度
注意:字节火山方舟对OpenAI SDK 的兼容性有点奇葩,不可直接填写模型名,需要提前在火山方舟控制台创建推理点,在推理点中选择要使用的模型,然后将推理点id填写到需要模型的地方,即软件中,如果觉得麻烦可以忽略,除了价格略低,并无其他优势。
查看如何创建推理点 https://www.volcengine.com/docs/82379/1099522
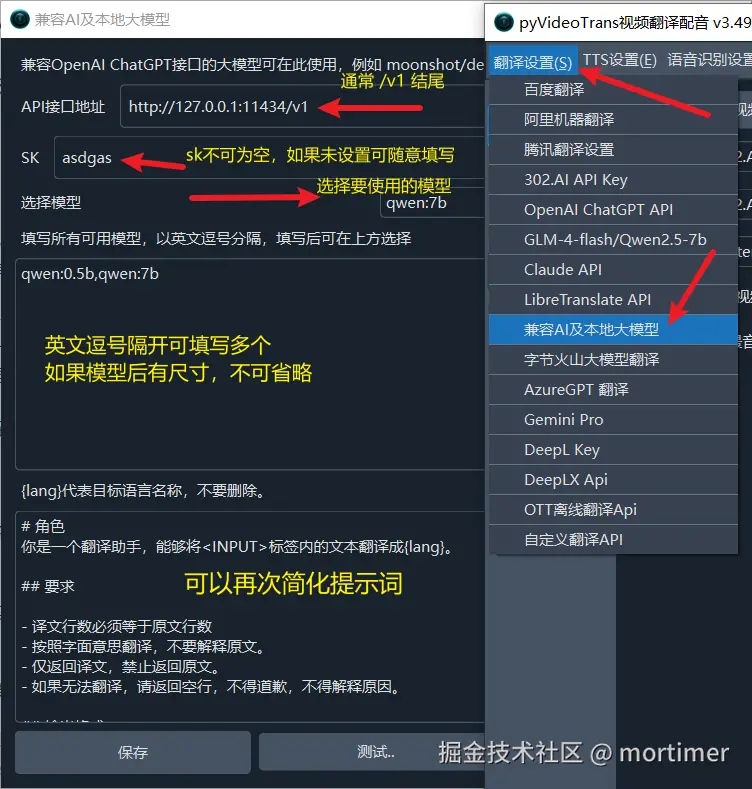
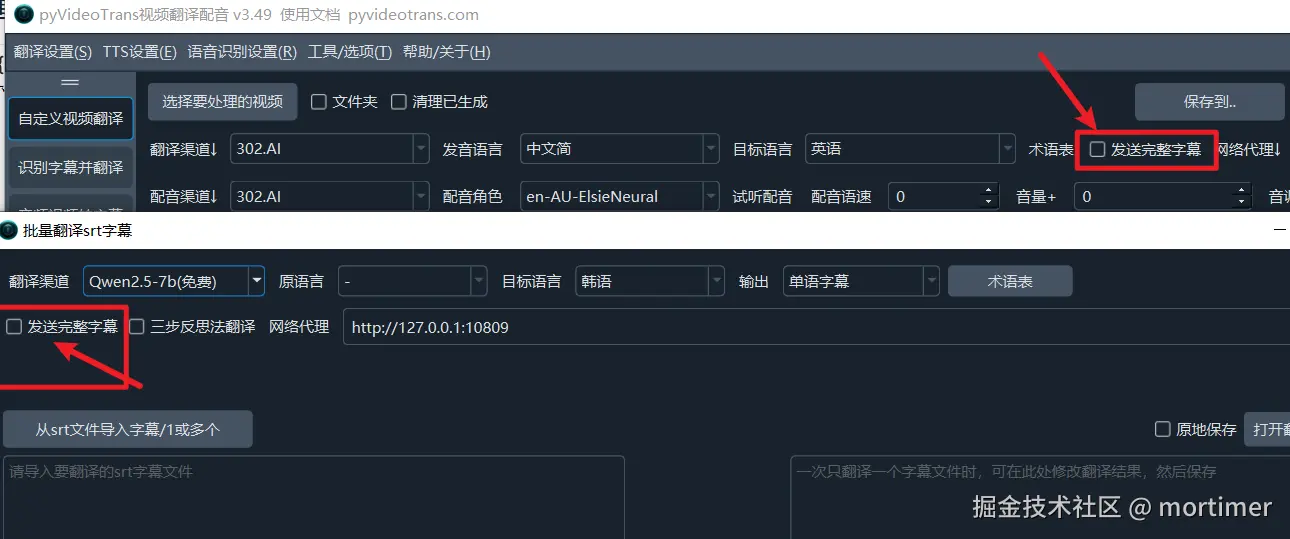
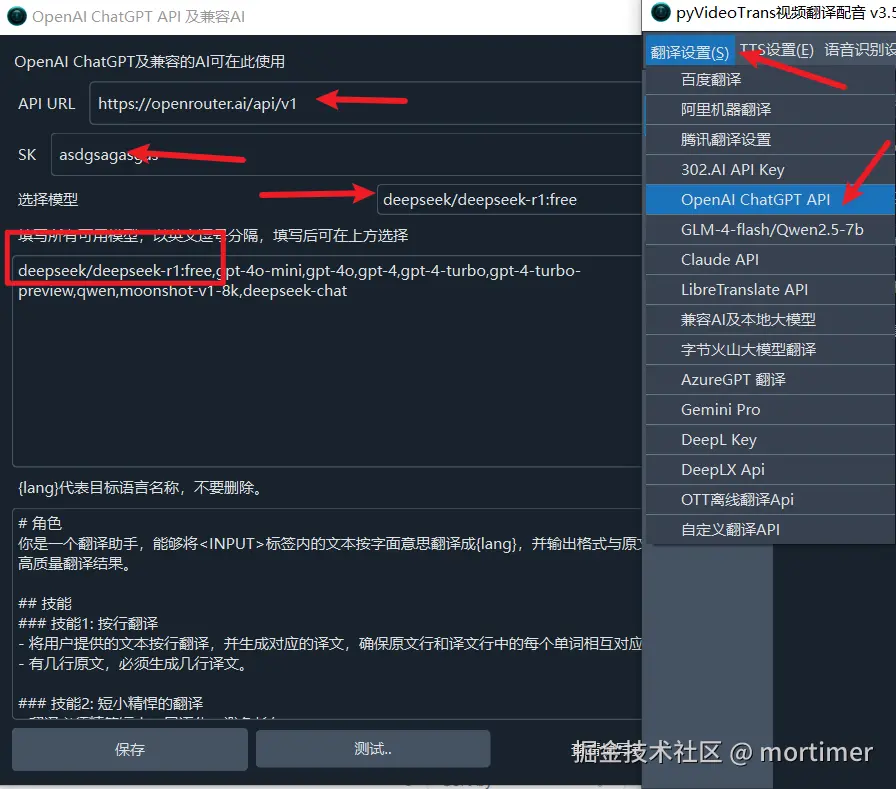
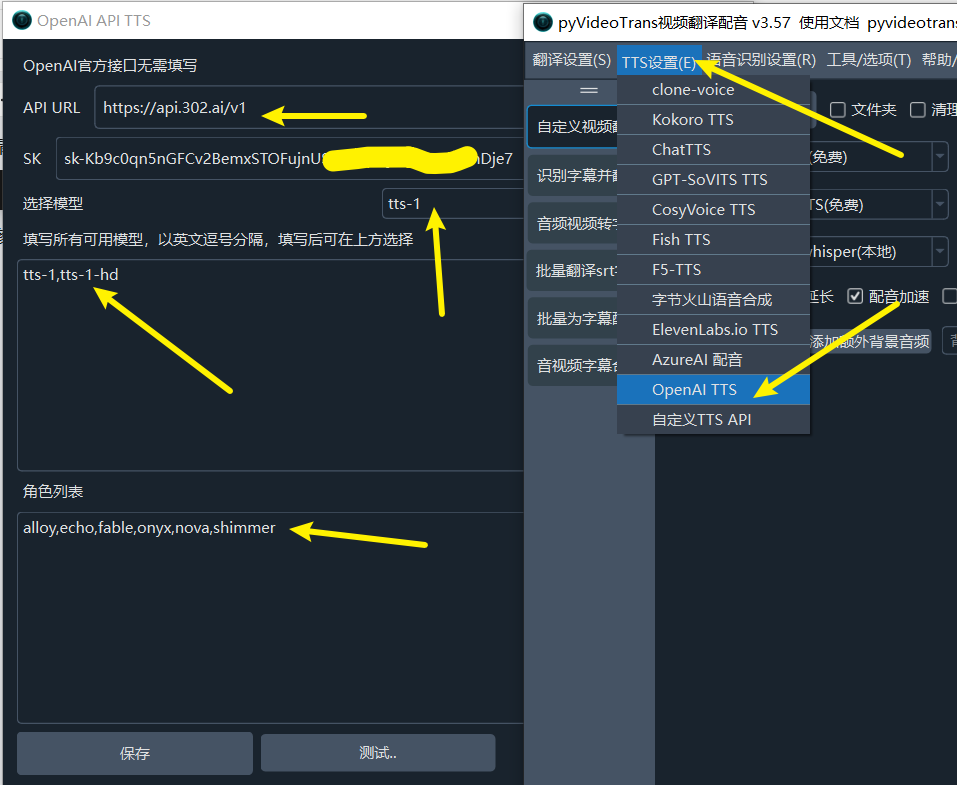
其他兼容 OpenAI API 的使用方法
本文仅列出部分AI使用方法,其他只要兼容 OpenAI API的服务均可使用类似方法,只要确定 API 接口地址 和 SK 以及 模型名称 即可。
注意 API URL 一般以 /v1结尾。